
Results

Publications
The following publications are directly connected to the project:
Wachsmuth & Bujna 2011: Henning Wachsmuth and Kathrin Bujna. Back to the Roots of Genres: Text Classification by Language Function. In: Proceedings of the 5th International Joint Conference on Natural Language Processsing (IJCNLP'11), AFNLP, Chiang Mai, Thailand, pages 632-640, November 2011.
Download [paper] (900 KB)
Wachsmuth et. al. 2011: Henning Wachsmuth, Benno Stein, and Gregor Engels. Constructing Efficient Information Extraction Pipelines. In: Proceedings of the 20th ACM Conference on Information and Knowledge Management (CIKM'11), ACM, Glasgow, Scotland, pages 2237-2240, October 2011.
Download [paper] (462 KB)
Prettenhofer & Stein 2011: Peter Prettenhofer and Benno Stein. Cross-lingual Adaptation using Structural Correspondence Learning. ACM Transactions on Intelligent Systems and Technology, ACM, to appear.
Wachsmuth et. al. 2010: Henning Wachsmuth, Peter Prettenhofer, and Benno Stein. Efficient Statement Identification for Automatic Market Forecasting. In: Proceedings of the 23rd International Conference on Computational Linguistics (COLING'10), ACM, Beijing, China, pages 1128-1136, August 2010.
Download [paper] (128 KB)
Prettenhofer and Stein 2010: Peter Prettenhofer and Benno Stein. Cross-Language Text Classification using Structural Correspondence Learning. In Proceedings of the 48th Annual Meeting of the Association of Computational Linguistics (ACL'10), Association for Computational Linguistics, Uppsala, Sweden, pages 1118-1127, July 2010.
Download: [paper] (540 KB)

Annotated Text Corpora
Annotated text corpora are used for the development and evaluation of text-based algorithms that include statistical or linguistic techniques. The following corpora are provided by the InfexBA project for the scientific community:
InfexBA Revenue Corpus, annotated German text corpus
Revised version: [Revenue-Corpus-v2.zip] (15.5 MB, contains all files)
Annotated XMI files: [revenuecorpus_annotated.tar.gz]
(6.3 MB)
Unicode plain text: [revenuecorpus_plain.tar.gz]
(5.3 MB)
corpus documentation [RevenueCorpus_Documentation.pdf]
(24 KB)
German text corpus annotated by domain experts for the development and evaluation of Information Extraction techniques for market information.
LFA-11 Corpus, annotated German text corpus
Revised version: [LFA-11-Corpus-v2.zip]
(6.7 MB)
Annotated XMI files: [lfa-11-corpus.tar.gz]
(4.9 MB)
corpus documentation: [lfa-11-documentation.pdf]
(64 KB)
German corpus with texts from two separated domains (music and smartphone) annotated by domain experts. It was designed for the development and evaluation of classfication algorithms for genre analysis (more precisely, language function analysis) and sentiment analysis.
Apache UIMA type system, XML descriptor file
XMI type system: [infexbaTypeSystem.xml] (12 KB)
Both corpora are preformatted for the framework Apache UIMA. So if you are working with UIMA, you can download the given type system file.

Free Software
RevMarker BA, Firefox Add-on, version 1.02, October 5, 2010
Download Add-on: [revmarker.xpi] (54 KB)
Short manual: [RevMarkerBA_GettingStarted.pdf] (519 KB)
This Add-on integates the InfexBA market analysis into browser Mozilla Firefox. Either automatically or after pressing a button, any currently opened webpage can be analyzed in order to highlight German statements on the revenues of companies and markets directly in the browser. Since version 1.02, there additionally is a feedback function to evaluated the correctness of the analysis results.
msx, webservice, version 1.0, August 20, 2010
webservice: http://jaslab.cs.upb.de:8080/msx/json?content={...}
documentation: [German] (80 KB, pdf) / [English] (76 KB, pdf)
This webservice for the market analysis is freely accessible. Notice that content extraction is done on client's side for performance reasons.
Sentiment Analysis, Web application
Online-Tool for the sentiment classification (positive vs. negative) of a German or Englisch text, which can be entered into a text field. This application is hosted at the InfexBA project page of the Bauhaus-University of Weimar.
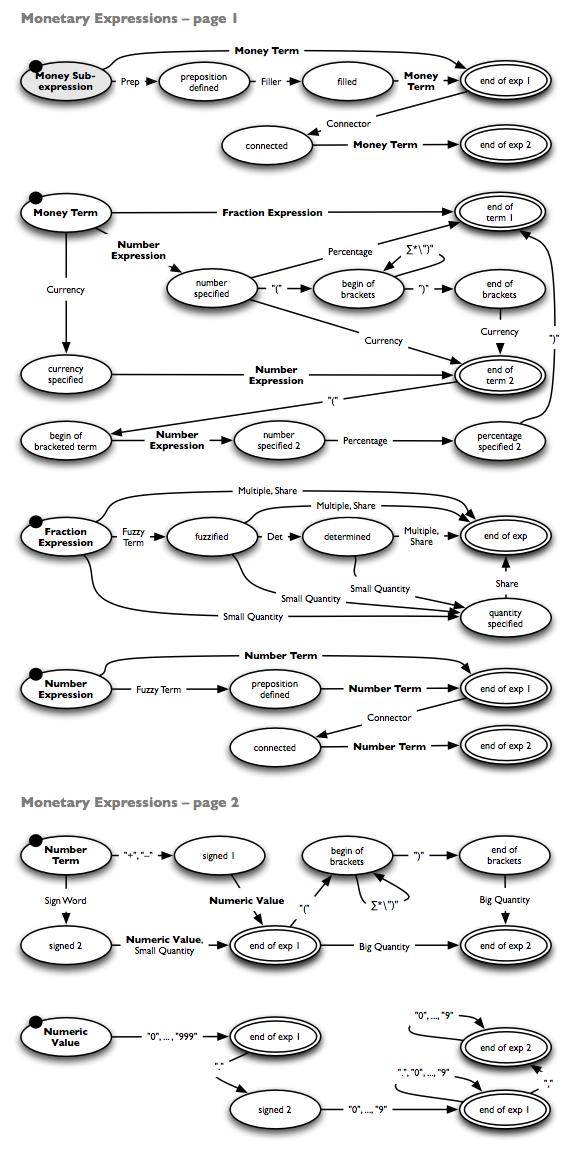
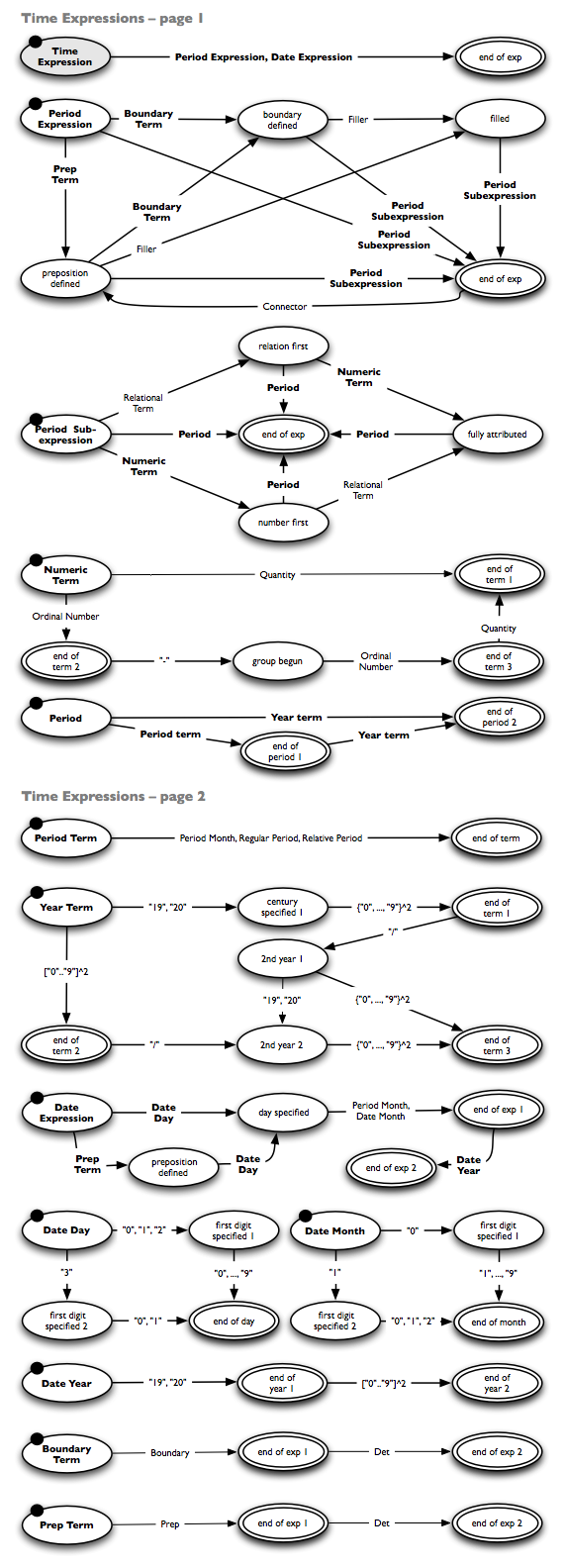
Time and money extraction, concept: regular expressions
{kind=link}
{kind=link}
The InfexBA market analysis consists of different extraction algorithms, as described in the paper mentioned above. The time and money recognition is based on the depicted finite state machines, which model regular expressions.
Language Function Analysis, Evaluation for the IJCNLP paper
Java source code and configuration files: [lfa-source.tar.gz] (248 KB)
Weka ARFF feature files [lfa-arff.tar.gz] (4.7 MB)
The following libraries are needed to compile and run the code: Apache UIMA (version 2.3), Weka (version 3.6, older versions might also work), LibSVM (version 2.x or newer), TreeTagger (and German model)